
(This article also exists in English.)
The LLaMA training data set with over 1.2 trillion tokens is reproduced and open source: The RedPajama project has set itself the goal of building a number of large foundation models open source to claim closed black box models such as GPT-4 to oppose something. The project has now completed the replication of the LLaMA dataset and is making it freely available to the public.
RedPajama: Cooperation for Open Source AI
Behind RedPajama is a coalition of top-class researchers from Canadian universities (Mila Québec, Uni Montréal), several research institutes at Stanford University (Stanford CRFM – Center for Research on Foundation Models; Hazy Research in the Stanford AI Lab), TogetherCompute, LAION, EleutherAI and others Partners who pool their expertise, research and hardware resources for the project. According to the blog post, RedPajama has set itself three goals:
- to pre-train a high-quality, broad-based data set,
- to train large base models (foundation models) on the data set,
- Fine-tune data and models as instructed to make base models secure and operational.
With the publication of the basic data set, the project has meanwhile completed the first step.
Motivation: White box instead of black boxes like ChatGPT
The most powerful foundation models are currently behind the APIs of commercial providers such as OpenAI, according to a blog post decentralized AI cloud provider Together on behalf of the project participants. Independent research into such models, personalization (taking into account different user needs) and their use for sensitive and confidential data are excluded by the access restriction.
There are already attempts to openly rebuild large AI models, but they do not yet offer the same quality and performance as the commercial large language models. For example, the grassroots AI EleutherAI presented the Pythia series on which Dolly 2.0 from Databricks is based, and the OpenAssistant project from LAION, led by Andreas Köpf and Yannic Kilcher, has published a free model including a high-quality open source data set . This was created as a crowdsourcing volunteer (man-made) and went through detailed review and moderation processes. Various models such as Pythia-12B served as a starting point, but also LLaMA – the LLaMA model levels cannot be published due to unresolved licensing issues.
Meerkat’s dashboard for exploring the GitHub subset in the corpus. The screenshot shows a preview.
(Bild: Hazy Research (Meerkat Repository))
LLaMA and GPT-4 distilled datasets legally non-free
Offshoots of the LLaMA, part research-only, part BitTorrent-leaked model, have the catch of operating in a legal gray area, as Meta AI has not released LLaMA under an open-source license. Only selected research projects can be granted legal access upon application. The resulting models are neither open source nor suitable for commercial use. Since then, a number of semi-open models have been circulating on the Internet: in addition to LLaMA, there are Alpaca (Stanford University), Vicuna, LLaVA and Koala (Berkeley University). In addition, numerous offshoots have used the OpenAI API to generate synthetic training data sets, which is a violation of the US provider’s terms of use.
OpenAI prohibits the use of its products to create competing products and reserves the right to take legal action against such projects. It is becoming apparent that this is not a paper tiger and is likely to be fought in court in the future: Microsoft has begun punishing customers who develop potential competitors for GPT-4 and is threatening to restrict their access to Bing search data. Microsoft is the largest financier and main investor in OpenAI, with exclusive rights to use their models.
Completely open, reproducible basic models
RedPajama is launched as a project with the goal of creating fully open and reproducible Foundation Models with the ability to compete with the world class. In addition to the Canadian and US research institutions mentioned (Mila Québec, Montréal, Stanford Center for Research on Foundation Models) and open source AI associations (LAION, EleuterAI), Ontocord.AI is a partner, a specialist in creating Training data sets for large foundation models with several billion parameters.
The starting point for the project was apparently the research paper on LLaMA, since its data set is considered to be particularly comprehensive, of high quality and well filtered. Also, a model as large as 7 billion parameters (like LLaMA) can run on most GPUs, which is a concern for the resource-constrained open source community. Since existing offshoots such as Alpaca, Vicuna, and Koala are available for research use only, the RedPajama target is a fully reproducible, open-source replica of LLaMA that is also open to commercial applications. In addition, research should also receive a more transparent pipeline for large AI models in this way.
RedPajama recipe for prep data on GitHub
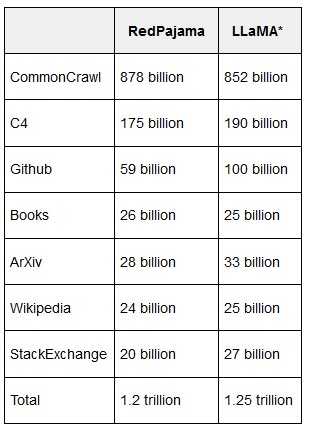
The basic data set is compressed in two sizes in a hugging face repository. It consists of seven different data sources:
- Common Crawl (gemäß Common Crawl Foundation Terms of Use)
- Colossal Clean Crawled Corpus: C4 (according to C4 license)
- GitHub (MIT, BSD, Apache only)
- arXiv-Paper (according to Terms of Use)
- Books (according to the_pile_books3 license and pg19license)
- Wikipedia (according to Wikipedia license)
- StackExchange (according to the license in the internet archive)

(Image: TogetherCompute)
Real-world data and the copyright issue
The lion’s share is made up of the common crawl of freely accessible internet data, with 878 billion tokens. C4 (Colossal Clean Crawled Corpus) is a Google-generated, heavily filtered standard dataset containing 175 billion tokens. The Washington Post, together with the Allen Institute, conducted a meticulous investigation into the Scrutinized 15 million websites entering C4 and the copyright symbol found in it about 200 million times, pirate sites (which make copyrighted material freely available) are said to be included in the dataset, and US news sites in particular are widely browsed for C4. There is also a scientific study independent of Google on the Colossal Clean Crawled Corpus.
59 billion tokens come from GitHub (the data is filtered by licenses and quality). Scientific articles from arXiv.org (28 billion tokens) are used to reduce repetition. A corpus of open access books (which the team de-duplicated to avoid bias, 26 billion tokens) was included in the books. Wikipedia contributed 24 billion tokens (a “subset” of Wikipedia pages was included in the training), and StackExchange contributed 20 billion tokens with a subset of websites popular there. Duplicates have been removed.
At least two of the data sources used are subject to the proviso that they could violate copyrights, as a copyright lawyer pointed out on Twitter: Common Crawl and the book collection “The Pile”, according to the Washington Post, however, C4 is also likely to be more problematic from a copyright point of view than previously thought. Vendors like OpenAI are evading scrutiny by no longer specifying what training data they used to create GPT-4. More detailed information on the preparation of the data and the quality filters can be found in the project’s GitHub repository. The recipes for preparing the RedPajama data can be recooked. This is significant because that Collect and clean data up to 90 percent of the effort in a machine learning project that uses real-world data (not synthetically distilled data).
DOE: Rechenkraft vom U.S. Department of Energy
According to the roadmap, the next step of the project is the training of a strong base model. That’s why RedPajama is part of the US INCITE program (with access to supercomputers from the Argonne Leadership Computing Facility of the US Department of Energy) and receives support from the Oak Ridge Leadership Computing Facility (OLCF for short), also supported by the US Department of Energy ( DOE). It is foreseeable that with the release of the training data set and future open models by RedPajama, a new wave of LLM offshoots will appear on the scene, this time open source instead of gray area. RedPajama is the beginning of a large project of open source, decentralized AI. The first models should appear “in the coming weeks”.
The RedPajama announcement can be found on the Together blog. The data set can be downloaded from Hugging Face. The data for reproducing the results is available on GitHub under the Apache 2.0 license. Anyone who wants to actively participate in the project can join the group’s Discord channel.
Update
20.04.2023
10:50
Clock
Added Washington Post contribution to data set C4.
(sih)