
Microsoft has introduced Kosmos-1, a Multimodal Large Language Model (MLLM) with visual and language capabilities. Kosmos-1 is said to be able to solve picture puzzles, recognize pictorial text, pass visual intelligence tests and follow natural language instructions. The property multimodal refers to the ability of a model to recognize input from several different types of perception and representation and to grasp it in context.
Individual modalities would be written text, oral speech, images, sounds, haptic impressions and motor movements in space. “Smelling”, interpreting and translating olfactory impressions would also be a modality, the representation of which is being researched in isolated projects in machine learning. Kosmos-1 combines two of these modalities: in addition to natural language, the image level and its contextual linking.
MLLM: create a kind of world model
The most exciting developments in the field of artificial intelligence are currently taking place at the intersection of the different modalities, which are now being successively merged: Taken by themselves, these capabilities in machine learning models are not new. So far there have been model classes such as DALL E from (Microsoft) OpenAI, Stable Diffusion or Midjourney, which create images on text instructions, and text generators such as the now increasing number of AI chatbots from different providers, which process language on a human-like level, “understand” and generate. The increasing connection of several such modalities in one model is new. The talk is then sometimes of world knowledge and “world models”, since these artificial neuronal networks are increasingly depicting facets of our world. The Microsoft team also uses the term World Model in its report to describe Kosmos-1 (the naming of the new model series is chosen accordingly).

Multimodal Large Language Model: Kosmos-1 understands visual and linguistic input in combination
(Image: Microsoft)
Combining computer vision with the wide range of capabilities of large language models is considered a step towards transformative artificial intelligence, which is increasingly penetrating areas of human perception with statistical methods. The creation of images, voices, sound and music on text instructions also falls into this area. Microsoft-OpenAI presented VALL·E at the beginning of the year, Google came out with AudioLM and MusicLM, and numerous other projects in the field of sound and speech synthesis as well as analysis and audio generation using AI are appearing this year.
Merge skills for multitasking
Providers such as Google and DeepMind are also doing intensive research in the direction of multimodality: In May 2022, the Google subsidiary DeepMind presented the multitasking-capable AI agent Gato. Gato takes up spatial and haptic aspects that could perspectively enable the control of a robot in space. DeepMind had advertised the agent with the symbolic image of a robot cat, and the scattered approaches are about multitasking. In order to come close to natural intelligence, more “perceptual” abilities are required than just language, and orientation and following instructions in space with haptic and motor elements should also be relevant in the long term for many areas such as industry. When training these models, there is a “cross-modal” transfer of knowledge, for example when verbal information is transferred to the visual or haptic area.
According to their own statements, research companies such as the Microsoft partner OpenAI are striving for “general artificial intelligence” (breaking latest news). Anyone aiming for such a broad general-purpose AI is currently working on combining different perception channels in models. Multimodality is not an invention of Microsoft or OpenAI. Other providers, such as the German AI company Aleph Alpha, have already presented models with MAGMA and their Luminous series that “understand”, explain, evaluate and further process images and texts in any combination and in the context. Their model family is an “MLLM” in the sense used by the Microsoft team.

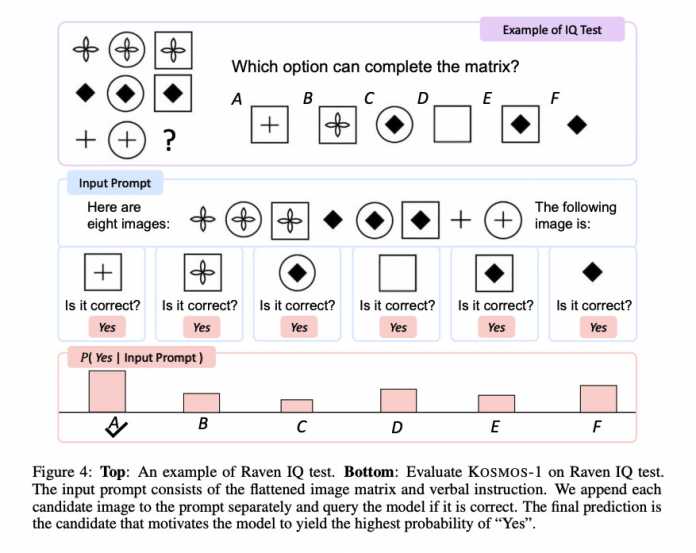
Raven’s test: an example from the visual IQ test that Kosmos-1 passed with moderate results at first.
(Bild: Microsoft, “Language is not all you need: Aligning Perception with Language Models”)
Kosmos-1: Training Data and Raven IQ Test
The training data from Kosmos-1 includes multimodal data collections such as text corpora, word-image pairs and material combining image and text, according to the Microsoft team. On the image side, among other things, LAION datasets were used, whereby apparently only images labeled in English were taken into account. On the text side, there were, among other things, excerpts from an 800 GB English-language text base called “The Pile” and the Common Crawl from the Internet, which is customary for large language models. Details on the training data can be found in the appendix of the arxiv paper.
According to the report, the team subjected the pre-trained model to various tests, with good results in classifying images, answering questions about image content, automated labeling of images, optical text recognition and speech generation tasks. According to the team, the rather moderate performance of Kosmos-1 in Raven’s Progressive Reasoning (RPR), a kind of visual IQ test, is striking. In doing so, test participants must complement sequences of shapes in a logically meaningful way. Here, Kosmos-1 was correct only 22 percent of the time. The team is still investigating the reasons for this, the paper says.
also read
Deepen pictorial reasoning
Visual reasoning, i.e. drawing conclusions about images without using language as an intermediate step, seems to be a key here, as the research teams explain in their reports. Microsoft’s recent research paper, “Language is not all your need: Aligning Perception with Language Models,” provides insight into the techniques used in merging the model’s visual and language capabilities.
Heidelberg researchers from the environment of the then ComputerVision Group (which also originated from Stable Diffusion, among other things) and from Aleph Alpha were the first to publish a method in 2021, to the best of our knowledge, with which generative AI models can be enriched (augmented) with multimodal capabilities. leave: “MAGMA – Multimodal Augmentation of Generative Models through Adapter-based Finetuning”. heise Developer had reported on the associated AI research model, whose source code, model map and weights have been available as open source on GitHub since last spring.
(sih)