
Three weeks before the launch of GPT-4 by OpenAI, Facebook’s parent company Meta presented its own large language model (LLM): the LLaMA (Large Language Model Meta AI) pre-trained with open data. Facebook Research made it available to the global AI research community after a quick check of each email address. The model was soon leaked and was available as a bit torrent – which invites you to experiment with it yourself. Whether and how the model may be used has not yet been finally clarified. One can assume that Meta doesn’t want to reverse its great popularity with legal disputes.
In contrast to ChatGPT and GPT-4, which are black boxes and do not offer any means of influence other than via prompts, LLaMA is an open model. You can run it on your own hardware and customize it. A research team at Stanford has succeeded in deriving a new model from the comparatively small LLaMA that can compete with ChatGPT. Thanks to the open training process, you know much better what is in the model and can operate it with less risk.
Anatomy of a language model
Modern language models are based on complex neural networks with different levels that work with tricks like the attention mechanism. The architecture is described as a transformer. The first such model was Google’s BERT (Bidirectional Encoder Representations from Transformers) and it revolutionized an entire industry:
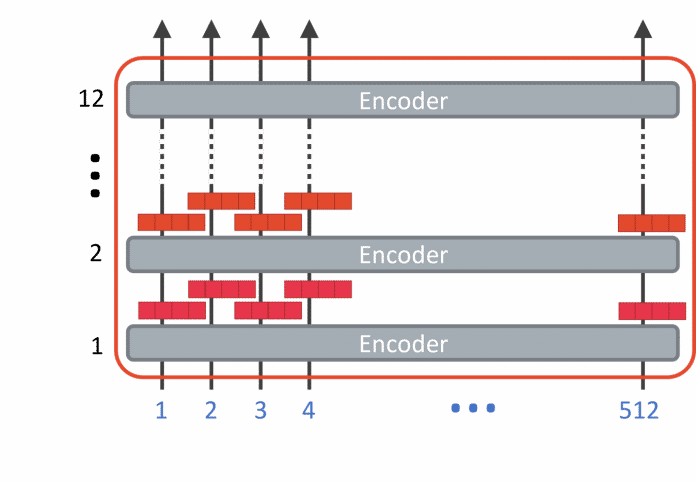
Basic architecture of BERT with 12 layers and up to 512 tokens (Fig. 1)
BERT is an application of Natural Language Processing (NLP). Its original version contained 120 million parameters, but over time the models have grown in size. This is due to the growing computing capacity, but also to the almost inexhaustible available training data – normal texts are sufficient for this. The training of such a model is enormously complex and places high demands on the hardware and computing power. For the prediction of tokens, i.e. the application, it is sufficient to evaluate the neural network. This also takes quite a while, even with reduced accuracy on CPUs, as will be shown later. In training, billions of parameters have to be adjusted in such a way that the best possible result is achieved.
This is associated with an enormous computational effort – Microsoft invested a billion US dollars in OpenAI in 2019 and will invest billions more. The company is currently buying thousands of Nvidia accelerators to set up a new supercomputer. For large language models, the cost of a single training run is in the millions.
Also, Meta’s LLaMA training was probably very expensive. The model is available in different sizes: with 7 billion, 13 billion, 30 billion or 65 billion parameters. All these parameters must be optimized in the training process. In the evaluation of the neural network, they are used to weight the vectors in the matrix multiplication and thus specify how complex the evaluation (i.e. the prediction of tokens) will be. The principle is similar for all Transformer models:
- A text is tokenized for training. In many cases, these are individual words, sometimes word components or combinations of words (entities). Each of these tokens corresponds to a specific number/position in the vocabulary.
- The numbers of the tokens of an entire paragraph are provided to the Transformer model as input in the first level of the neural network. In the picture above (Fig. 1) this can be up to 512 tokens. This context length can assume higher values for large models.
- For this paragraph, the data is propagated throughout the Transformer network.
- The result is a probability distribution for a new token that represents the word that goes well with the previous paragraph. This token is issued.
- The process then starts again, but then with one more token than before.
Forward propagation (in this case the prediction of tokens) in a neural network is represented by a matrix multiplication. Corresponding values are multiplied with each other and the result is added up. For each token to be predicted, that is many billions of multiplication and addition steps. This is also the reason why this process works much faster on graphics cards (GPUs) than on CPUs: Since the operations correspond to those when rendering graphics, graphics cards are optimized for them and can carry them out in parallel with their many hundreds (or thousands) of shaders . Compared to CPUs, this saves a large part of the previous waiting time.
Language models on the CPU
Can language models be operated with only one graphics card? A cluster of (professional) GPUs is essential for training. With a lot of patience, you could previously have the prediction of large language models done purely by CPUs.
If you experiment with ChatGPT, you will inevitably feel the need to try out models of this type on your own hardware. The leak of the model has motivated some developers to make the method available on CPUs with approximations (i.e. approximations). With the approximate values, they can calculate quickly enough that you don’t have to wait too long for results.
This requires some restrictions:
- The weights in the original model are stored as 32-bit floating point numbers. Since CPUs are too slow for such calculations, the process should be shortened to 16 bits.
- But even with that, the calculation doesn’t work fast enough. Therefore, these 16-bit numbers are quantized to just four bits.
- The models can then be evaluated. It’s so sluggish that you can almost read along.