
In September last year, Nvidia announced the new GPU architecture Ada Lovelace, and launched consumer entertainment products GeForce RTX 4090 and 4080. By the end of January this year, based on this architecture, they officially launched the professional graphics desktop workstation GPU product RTX 6000 Ada Generation, and the data center GPU product L40. At the GTC 2023 Spring Conference held in the second half of March, Nvidia continued to launch more products using this architecture.
In terms of professional graphics GPUs, they released a variety of products for notebook workstations, such as: RTX 5000, RTX 4000, RTX 3500, RTX 3000, RTX 2000 with Ada Lovelace behind the model name;
For desktop workstations, a new RTX 4000 SFF that emphasizes the compact appearance and size has been added; and in the GPU part of the data center, Nvidia has launched the second new model L4 using the Ada Lovelace architecture, which is what we want to sort out first. The product.

From the perspective of public cloud operators, Google Cloud Platform has announced that it will launch a new GPU execution individual service G2, which will use Nvidia L4, and has entered the private preview stage. regions are served.
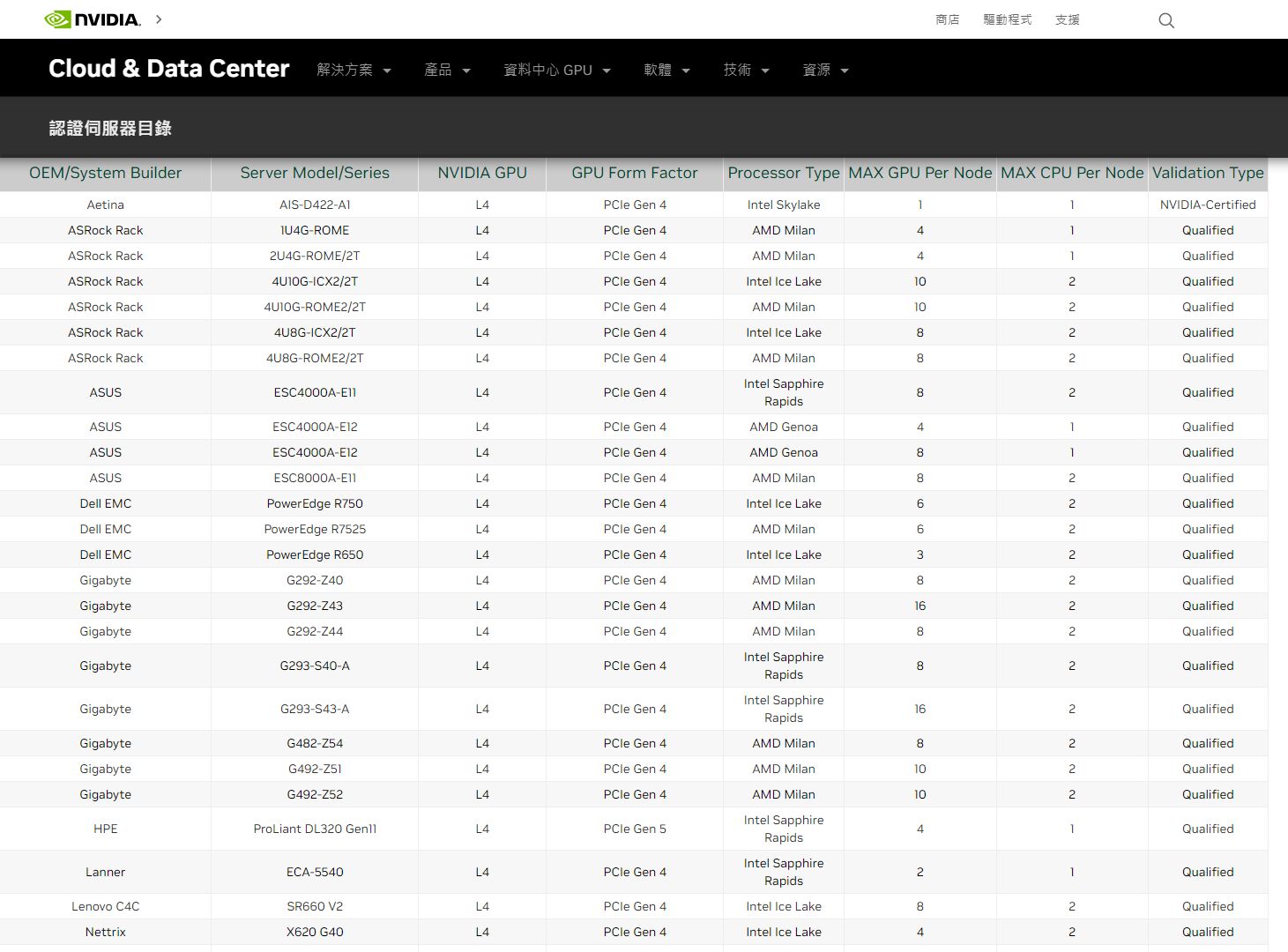
In terms of servers, Nvidia announced that more than 30 manufacturers will provide this GPU. According to the company’s certification server directory, there are 12 brands and a total of 40 models that have passed the certification.
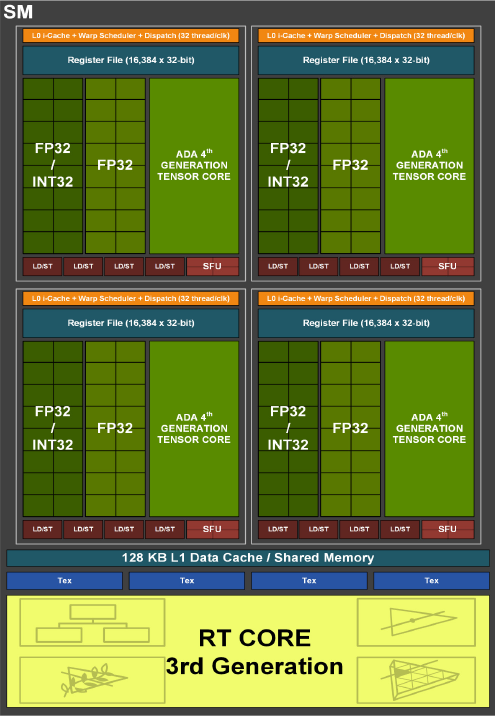
It is worth noting that, compared to the past two waves of product releases, Nvidia has also updated the Ada Lovelace architecture white paper to version 2.0 this time – in addition to following the white paper version 1.01, it lists the first wave of GeForce RTX 4090 listed (GPU code AD102) , GeForce RTX 4080 (GPU code-named AD103), also included in the L40 (GPU code-named AD102) and L4 (GPU code-named AD104) that debuted in the first quarter of this year. These GPUs all use the same basic architecture.
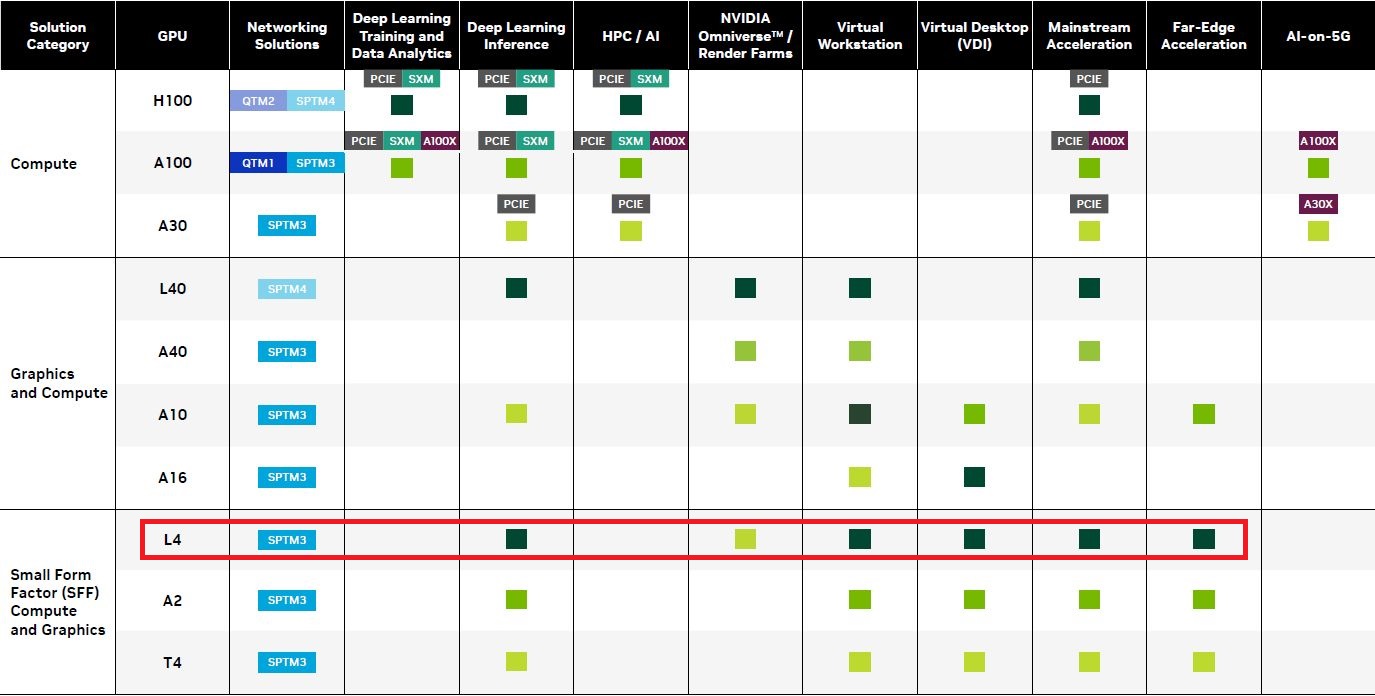
In terms of product positioning, L4 has another task, which is to replace the universal GPU product T4 launched 4 years ago. It can respond to AI video processing, visual computing, graphics processing, GPU virtualization/virtual workstation, generative AI, as well as many applications in the field of edge computing, can help create theater-level real-time renderings and scenes with more detailed details to provide an immersive visual experience.
Nvidia said the T4 has seen widespread adoption and is currently Nvidia’s most-shipped data center GPU. Although they have not announced the number, however, the three major public cloud operators have provided individual execution services that can be used with T4 (AWS Amazon EC2 G4dn series, Azure NCasT4_v3 series, and GCP’s 18 regional data centers around the world provide individual execution services that can be used with T4 ); In terms of servers, according to the Nvidia certified server directory page, there are currently 39 brands with a total of 444 models.
In terms of hardware and software configuration, what are the characteristics of Nvidia’s latest L4 this year? This GPU has built-in 7,424 Ada Lovelace architecture CUDA cores (T4 has 2,560 Turing architecture CUDA cores), 232 fourth-generation Tensor cores (T4 has 320 second-generation Tensor cores), 58 third-generation RT cores ( T4 is 40 first-generation RT cores), 24 GB GDDR6 memory (T4 is 16 GB), and uses PCIe 4.0 interface (T4 is 3.0).
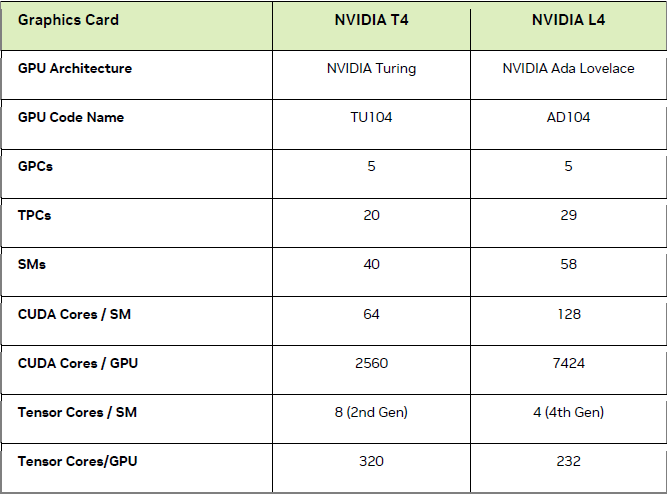

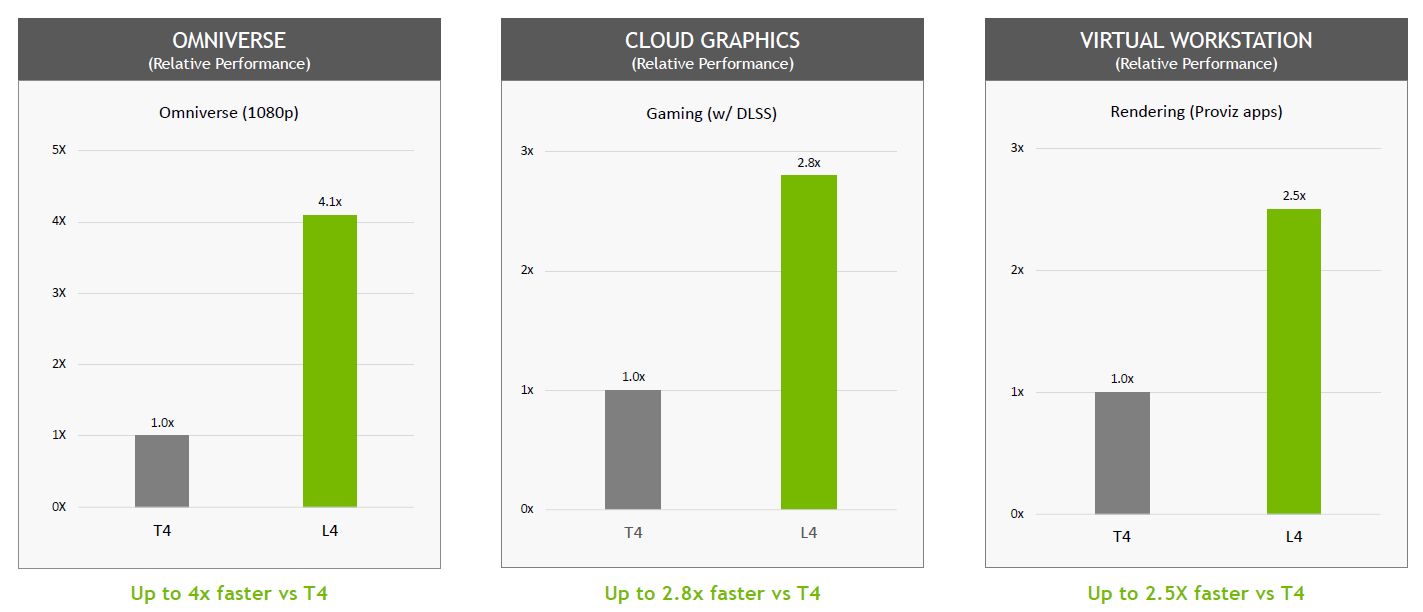
If it is used in the Omniverse metaverse virtual environment developed by Nvidia, what is the capability of L4? According to their tests, in the state of enabling DLSS 3 technology, for AI-based avatars (AI-based avatars) real-time coloring processing (Rendering), according to their tests, the performance of L4 can reach 4.1 times that of T4; if used For cloud game streaming, the processing performance of L4 for ray tracing technology is 3.3 times that of T4, and the key is that L4 adopts a new generation of RT core.
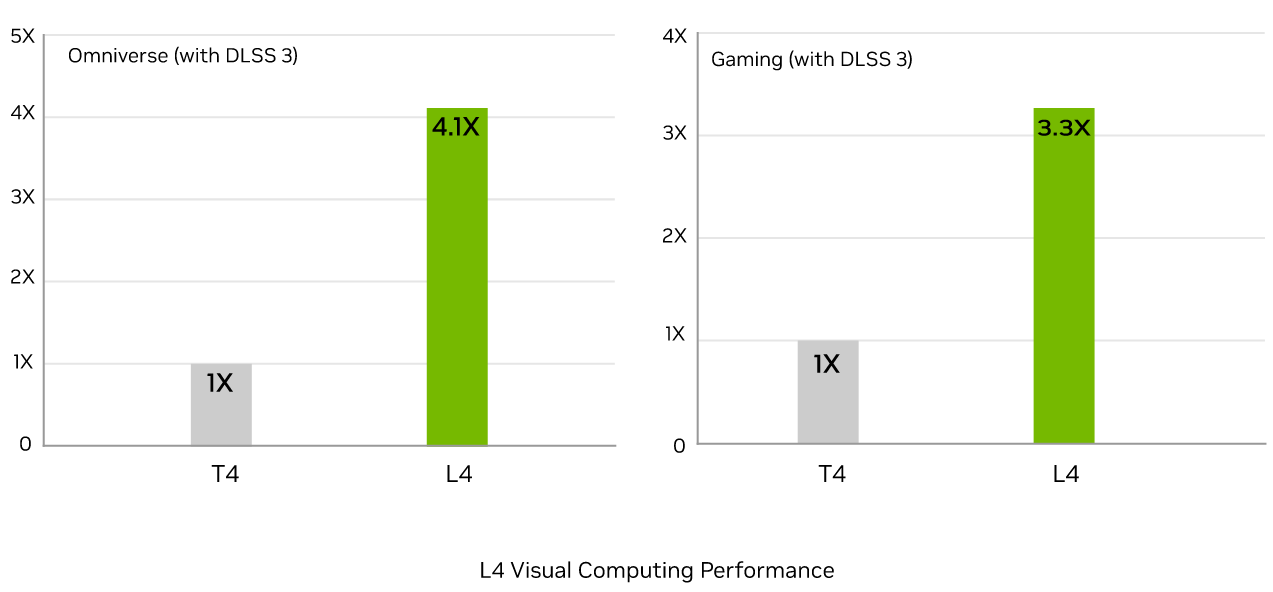
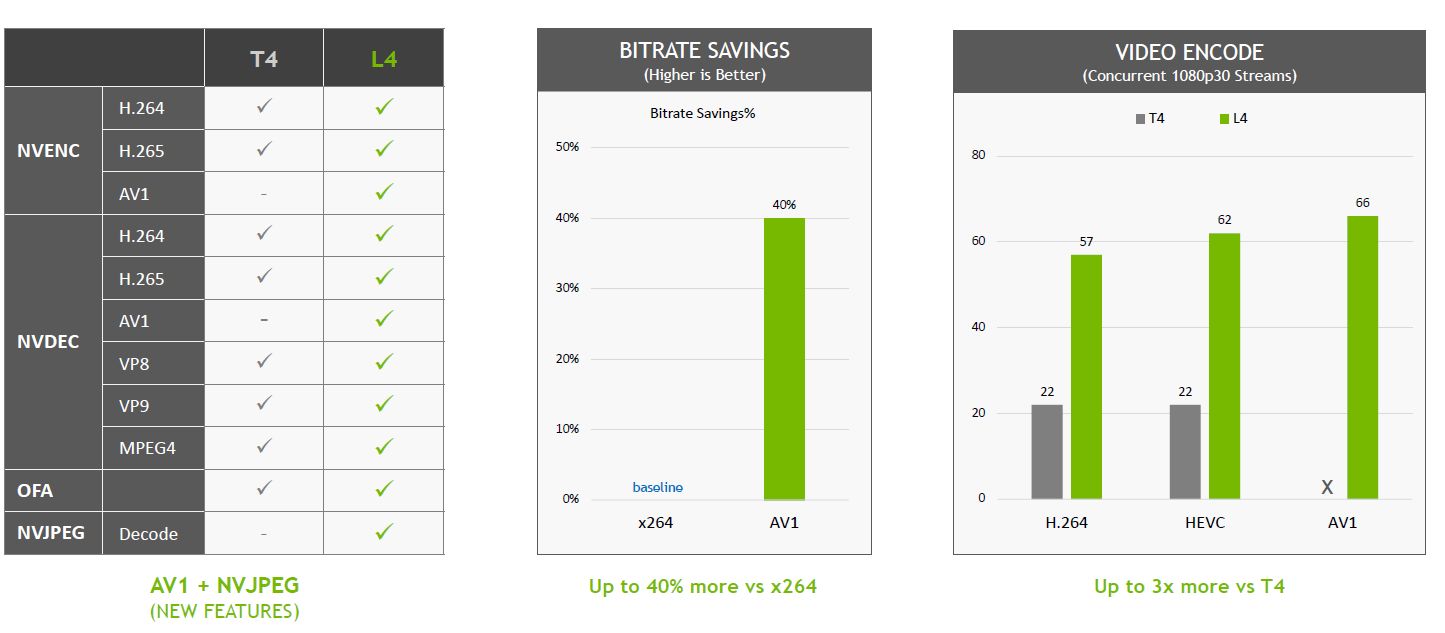
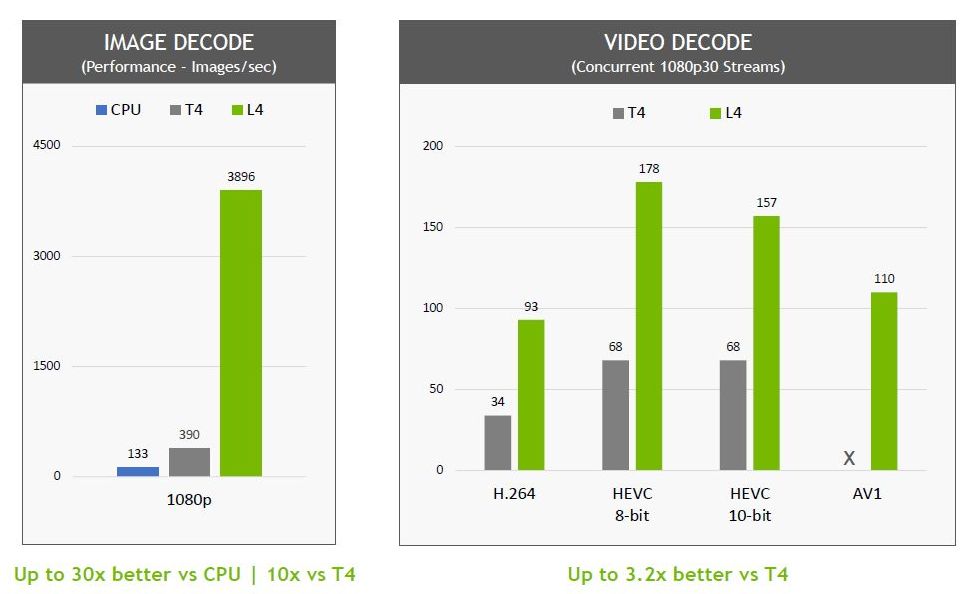
In the process of image decoding, L4 can provide 10 times the performance of T4, and in the processing of video decoding, L4 can provide 3.2 times the performance.
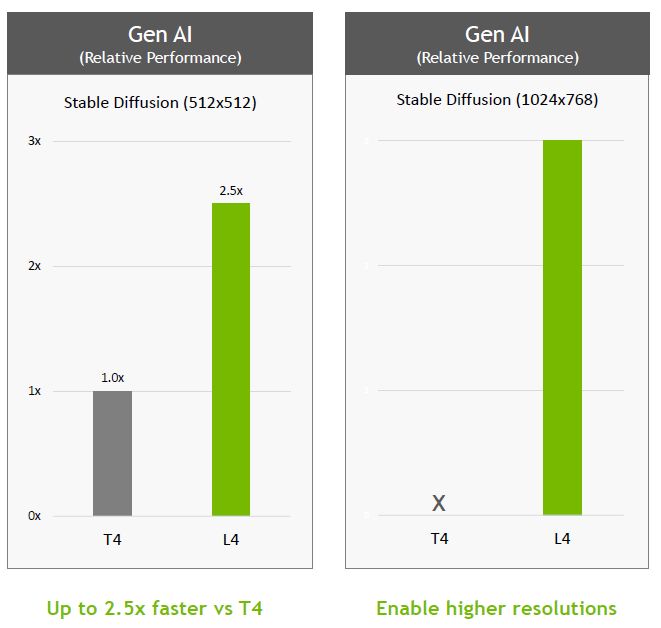
In the application of generative AI, if T4 is used as the benchmark, the newly launched L4 can provide 2.7 times the performance. Since the built-in GPU memory capacity is increased by 50% (L4 is 24 GB, T4 is 16GB), so it can Handles image generation at larger sizes (resolutions up to 1024 x 768).
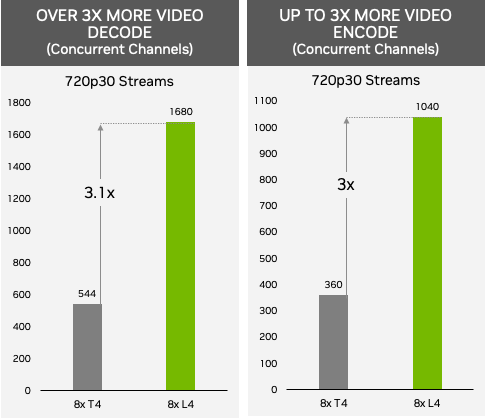
Regarding the real-time processing of AI video, such as video streaming for millions of viewers, or providing immersive AR or VR experience, if the service is provided by a server with 8 L4, according to Nvidia’s test , 720p30 resolution mobile phone video streaming channels that can be played at the same time, can provide more than 1,000 (AV1 encoding 1,040, H.264 decoding 1,680), if equipped with 8 T4 servers, mobile phone video streaming that can be played simultaneously Only one-third the number of channels (360 for H.264 encoding and 544 for H.264 decoding).
For various application requirements of visual computing and high-performance computing, L4 can provide up to 4 times more performance.
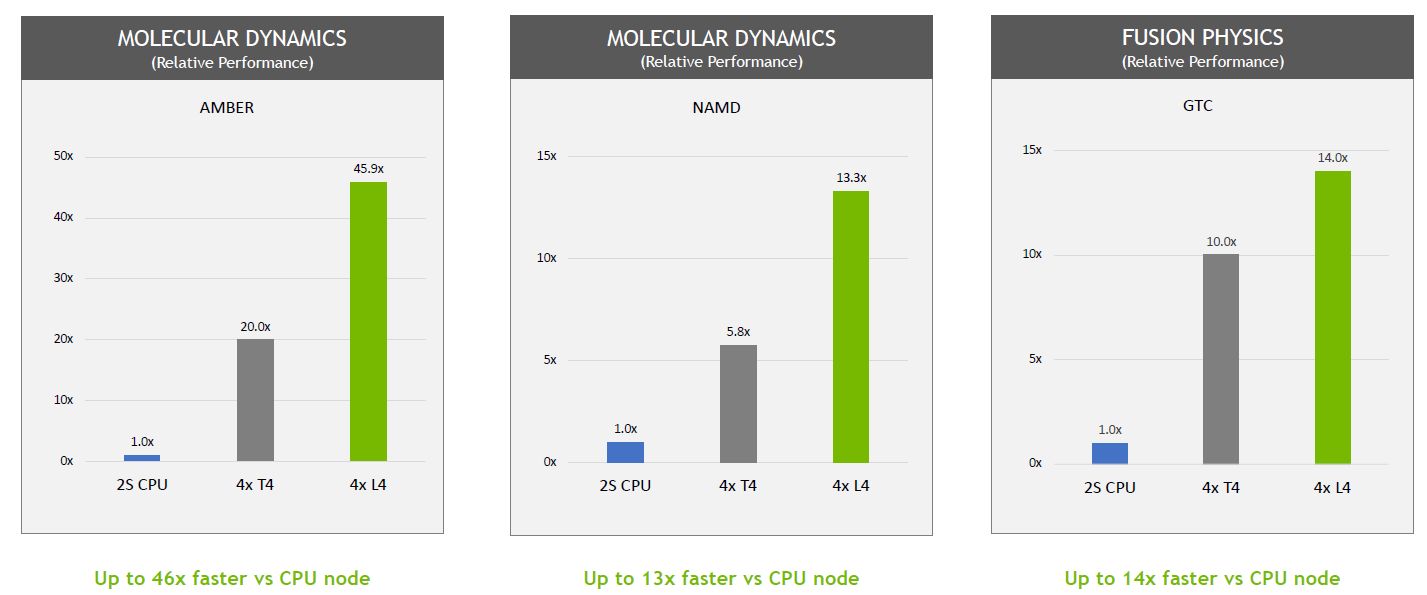
In the application of computer vision, L4 is equipped with the CV-CUDA library released by Nvidia at the GTC conference. Because it has a built-in fourth-generation Tensor core, supports FP8 precision, and provides 1.5 times the GPU memory capacity, it can In every link of related processing, for example, after the video and picture are input to the server, and before output from the server, such as decoding, pre-processing, inference, post-processing, encoding and other stages, it provides powerful computing processing performance.
Based on the 2-way server using the Intel Xeon Platinum 8380 processor, with 8 L4 servers, it can provide 120 times the AI video processing performance. Enterprises and organizations can use this real-time analysis capability to provide personalized content Recommend, improve search relevance accuracy, detect object type content, and build smart environmental space solutions.

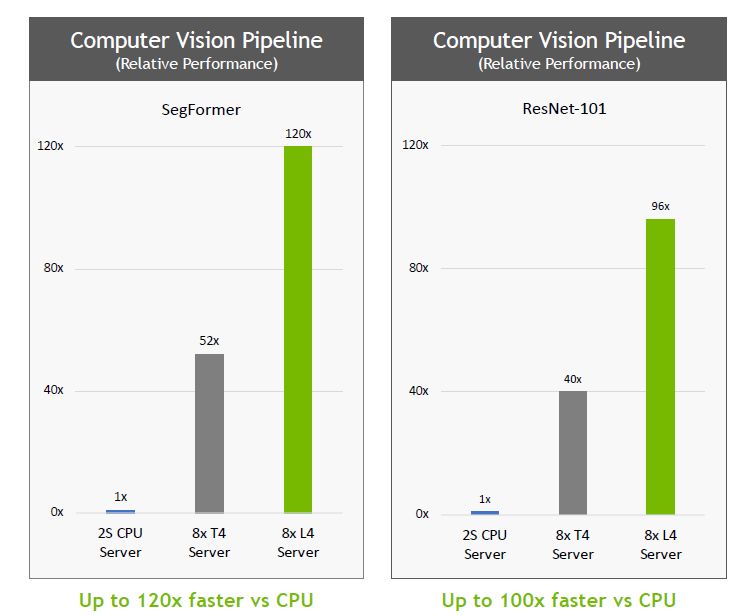
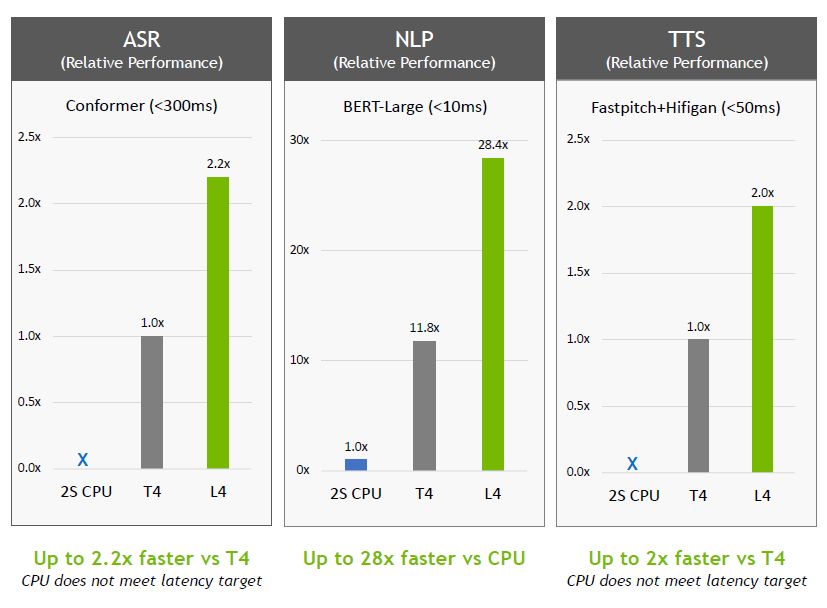
In the results of the MLPerf Inference 3.0 benchmark test released on April 5, the performance of L4 can reach 3 times that of T4 for the BERT model accuracy level test items. Nvidia believes that the reason is that the Ada Lovelace architecture adopted by L4 includes support for FP8 precision. The fourth-generation Tensor core can provide excellent performance under high-precision requirements.

Another factor is that L4 is equipped with a larger-capacity L2 cache (48 MB), plus MLPerf Inference 3.0 implements two important software optimization mechanisms: cache residency (cache residency), cache persistent management (persistent cache management), and can make good use of L2 cache. In terms of the former, when the MLPerf workload can be fully loaded into the L2 cache of the GPU, it can enjoy higher bandwidth and less power consumption than GDDR memory. According to Nvidia’s observations, if the performance when the data volume of batch processing is set to the maximum in the past is used as a benchmark, when the data volume configuration is adjusted, the entire workload can be completely placed in the L2 cache, and the maximum performance Gain a 40% potency boost.
The continuous use feature of L2 cache is provided by Nvidia in the current main GPU architecture Ampere. Developers can use this feature to realize a single call of TensorRT, which can mark a subset of L2 cache, making this This feature is especially useful for inference processing, because under such a resource resident management mechanism, developers can align the resources that have been reused for layer activations when executing across models. ) memory, which can dynamically reduce the write bandwidth consumption of GDDR memory.
In terms of product appearance and energy-saving and carbon-reducing benefits, both L4 and T4 have similar features. For example, they both adopt a low-profile, single-slot PCIe interface card appearance, and their thermal design power consumption is more than 70 watts (L4 is 72 watts, T4 is 70 watts).
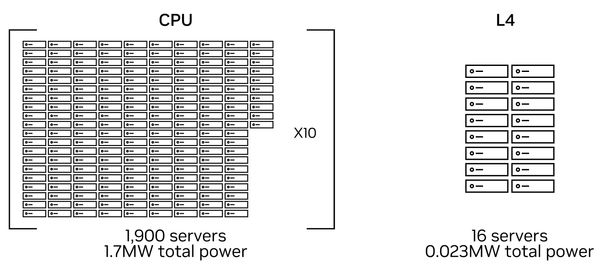
Based on the high energy efficiency of L4, Nvidia emphasized that a small number of servers with Nvidia L4 can replace a large number of CPU-based servers. According to their assessment, 1,900 pure CPU servers were originally needed for computer vision processing and PyTorch inference, which consumed a total of 1.677 million watts of electricity, enough to supply nearly 2,000 households for one year, equivalent to 172,000 trees The carbon emissions that can be reduced by more than 10 years of growth; if it is replaced with a GPU server equipped with 8 Nvidia L4s, and the CV-CUDA developed by Nvidia is used for pre-processing and post-processing, as well as the TensorRT inference platform, only 16 For one server, the total power consumption can be significantly reduced to 23,000 watts.
Product Information
Nvidia L4
●Original manufacturer: Nvidia
●Suggested price: not provided by the manufacturer
●Architecture: Ada Lovelace
●Code name: AD104
●Number of CUDA cores: 7,424
●Number of Tensor cores: 232 (fourth generation)
●Number of RT cores: 58 (third generation)
●Built-in memory capacity: 24 GB GDDR6
●Memory bandwidth: 300 GB/s
●Video processing engine: 2 encoders, 4 decoders, 4 JPEG decoders
●Connection interface: PCIe 4.0 x16
Support NVLink: no
●FP32 single-precision floating-point performance: 30.3 TFLOPS
●Appearance size: single slot low version
●Power consumption: 72 watts
[Note: Specifications and prices are provided by the manufacturer, subject to change from time to time, please contact the manufacturer for correct information]