
57.7 billion transistors, AMD Navi 31 officially debut!!
Code-named Navi 31, brand-new RDNA 3 GPU microarchitecture, AMD’s new high-end Radeon RX 7900 XTX graphics card officially debuted, and it is the first gaming GPU product in the market that uses Chiplet multi-chips.Consists of 1 5nm GCD and 6 6nm MCD chips, with improved Shader Engine design2nd generation 96MB Infinity Cache with 24GB GDDR6 memory, upgraded 2nd generation Ray Accelerators ray tracing engine, compared with the previous generation, the performance has been greatly improved by +54% under the same power consumption, and it has better cost performance than the rival GeForce RTX 4080 .
In terms of positioning, AMD will launch two models of Radeon RX 7900 XT and RX 7900 XTX on December 13. The RX 7900 XT has 84 CUs, 5,376 Stream Processors, 84 RT accelerated computing units, and 168 AI accelerated computing units. , with 320-bit memory interface, 20GB GDDR6 memory, the official price is US$899.
RX 7900 XTX has a complete 96 CUs, 6,144 Stream Processors, 96 RT accelerated computing units, 192 AI accelerated computing units, 384-bit memory interface, 24GB GDDR6 memory, and the official price is US$999.
AMD Radeon RX 7900 Family Full Specifications
| GPU Architecture | RDNA3 | RDNA3 |
| Transistor Count | 57.7 billion | 57.7 billion |
| Die Size | 300 + 220 mm² | 300 + 220 mm² |
| Compute Unit | 84 | 96 |
| Ray Accelerators | 84 | 96 |
| AI Accelerators | 168 | 192 |
| Stream Processors | 5,376 | 6,144 |
| Game GPU Clock | 2,000 | 2,300 |
| Boost GPU Clock | 2,400 | 2,500 |
| Peak Single Precision | 52 TFLOPS | 61 TFLOPS |
| Peak Half Precision | 103 TFLOPS | 123 TFLOPS |
| Peak Texture Fill-Rate | 810 GT/s | 960 GT/s |
| ROPs | 192 | 192 |
| Peak Pixel Fill-Rate | 460 GP/s | 480 GP/s |
| Infinity Cache | 80 MB | 96 MB |
| Effective Memory Bandwidth | 2,900GB/s | 3,500GB/s |
| Memory Bus Interface | 320-bit | 384-bit |
| PCIe Interface | PCIe 4.0 x16 | PCIe 4.0 x16 |
| Board Power | 315W | 355W |
The first Gaming GPU with Chiplet architecture
One of the major improvements in the microarchitecture of RDNA 3 GPU is the adoption of the chiplet design, which is changed from a single chip in the past to one 5nm GCD chip with six 6nm MCD chips. You must know that the cost of TSMC 5nm and 6nm has increased by 70%, but 5nm and 6nm SRAM The chip area and performance are almost the same. In addition, the GDDR6 memory controller PHY is an analog circuit, which consumes a large physical area. Therefore, AMD splits the Infinity Cache and memory controller into MCD chips, and the cost of use is cheaper. 6nm process, and then the Graphics Engine, which requires higher clock speed and higher density, will be transferred to a more advanced 5nm process, so that RDNA 3 GPU has the characteristics of high density, high yield and low cost at the same time.
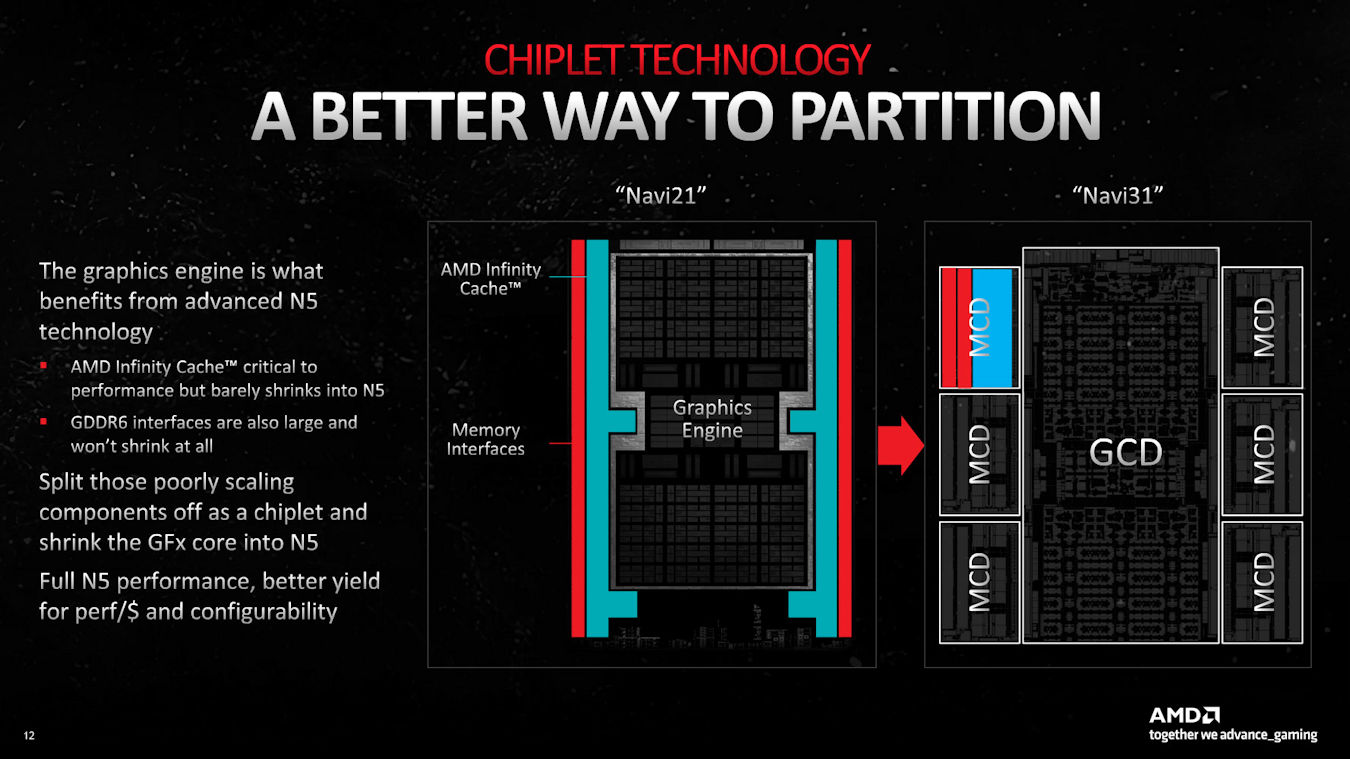
In order to realize the chiplet architecture of RDNA 3 GPU, AMD adopts the new Infinity Link and Die-to-Die Fanout Rounting connection technology, and 6 MCDs use 1mm ultra-short-distance wiring to achieve a total bandwidth of 5.3TB/s, even in terms of delay. The previous generation RDNA 2 has been reduced by 10%. According to AMD, RDNA 3 benefits from the Chiplet architecture. After separating the Infinity Cache from the memory controller, the GCD chip can operate at a higher clock speed. The Radeon RX 7900 XTX Game Clock is preset to 2.3GHz and Boost Clock is 2.5GHz. Compared with the previous generation, it has increased by about 10%, and it is also air-cooled and overclocked to the 3GHz level without any problem.
Improved RDNA 3 GPU microarchitecture

The new RDNA 3 GPU micro-architecture has greatly improved the Compute Unit. The Shader Engine of the Navi 31 graphics core has been increased from 4 to 6. Each Shader engine has 2 Graphics Array computing groups. Each Graphics Array computing group contains The number of Dual Compute Units (DCUs) is reduced from 5 to 4, so the number of Dual Compute Units in each Shader Engine is reduced from 10 to 8, and they are shared. After adjustment, the Shader Engine design can be more effective for a total of L1 Cache , Rasterizer, RB+, Prim Unit and other resources, a total of 96 CU units in the entire chip have increased by 20%.
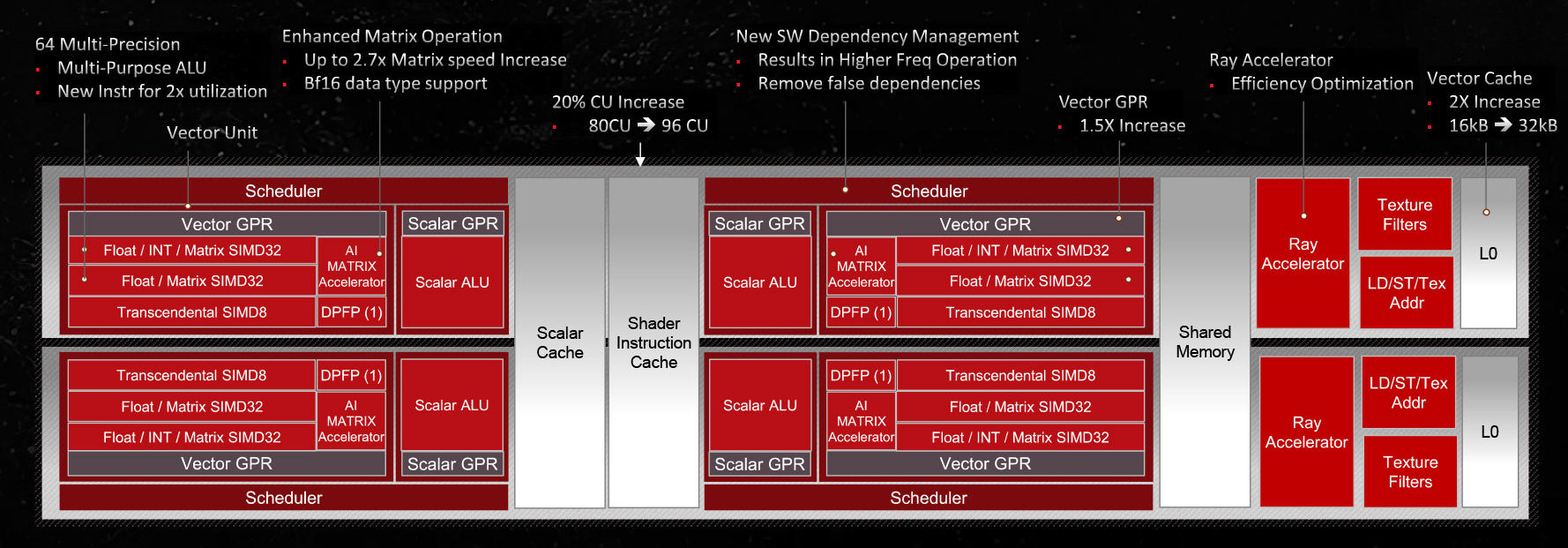
Each generation of the RDNA architecture is improved for CU design. The Vector Cache (L0) capacity is increased from 16KB to 32KB, and the number of Vector GPR registers is increased by 50%. At the same time, an improved 64 Way multi-precision and multi-functional SIMD design is added. The number of SIMD32 From 2 to 4, each Vector Unit can execute 1 Wave64 FMA instruction or 2 Wave32 ( 1 Int + 1 Float / 2 Float) instructions in a single cycle. These changes have improved the IPC performance of RDNA 3 by about 17.4%.
In addition, RDNA 3 has improved thread management performance for the Scheduler scheduling unit. This change allows the RDNA 3 microarchitecture to operate at a higher clock rate, and benefiting from TSMC’s 5nm process progress, making Navi 31 the first to surpass the CPU at room temperature. 3GHz GPU.
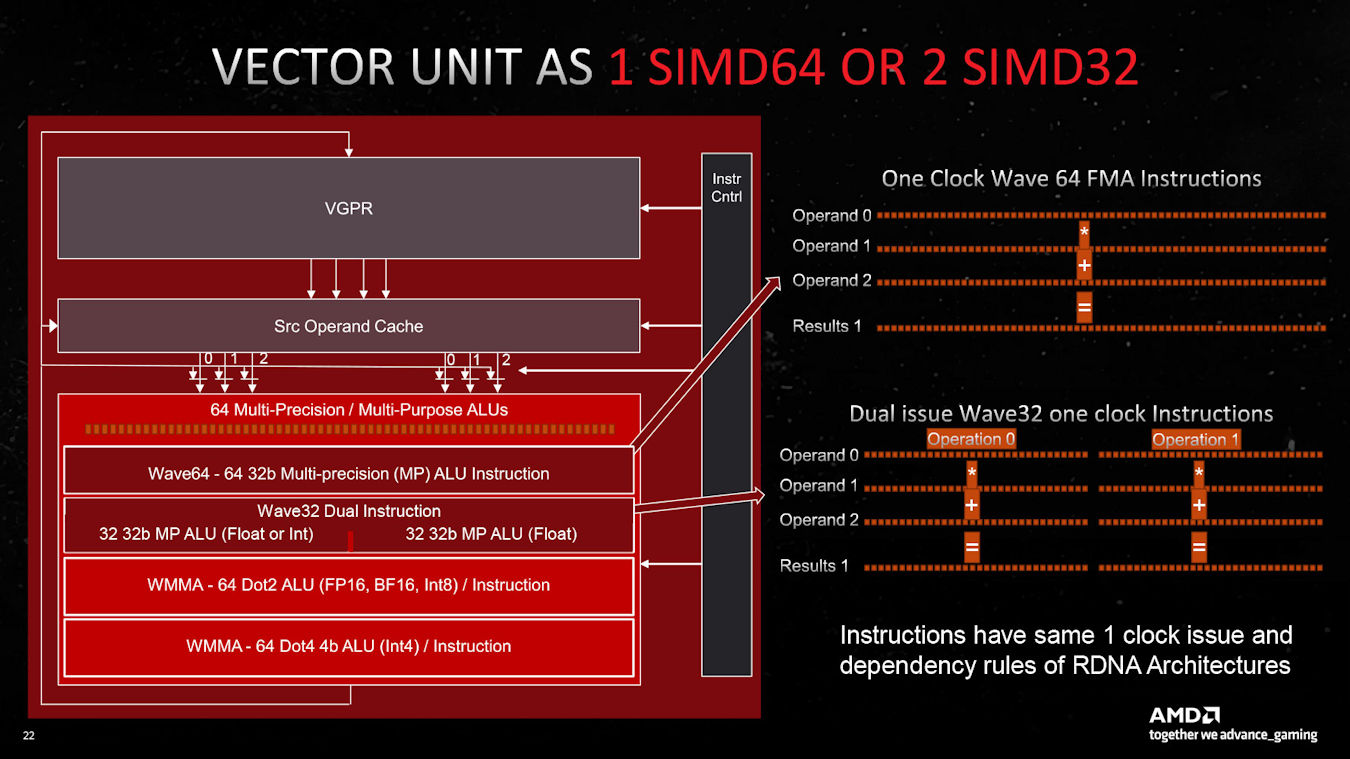
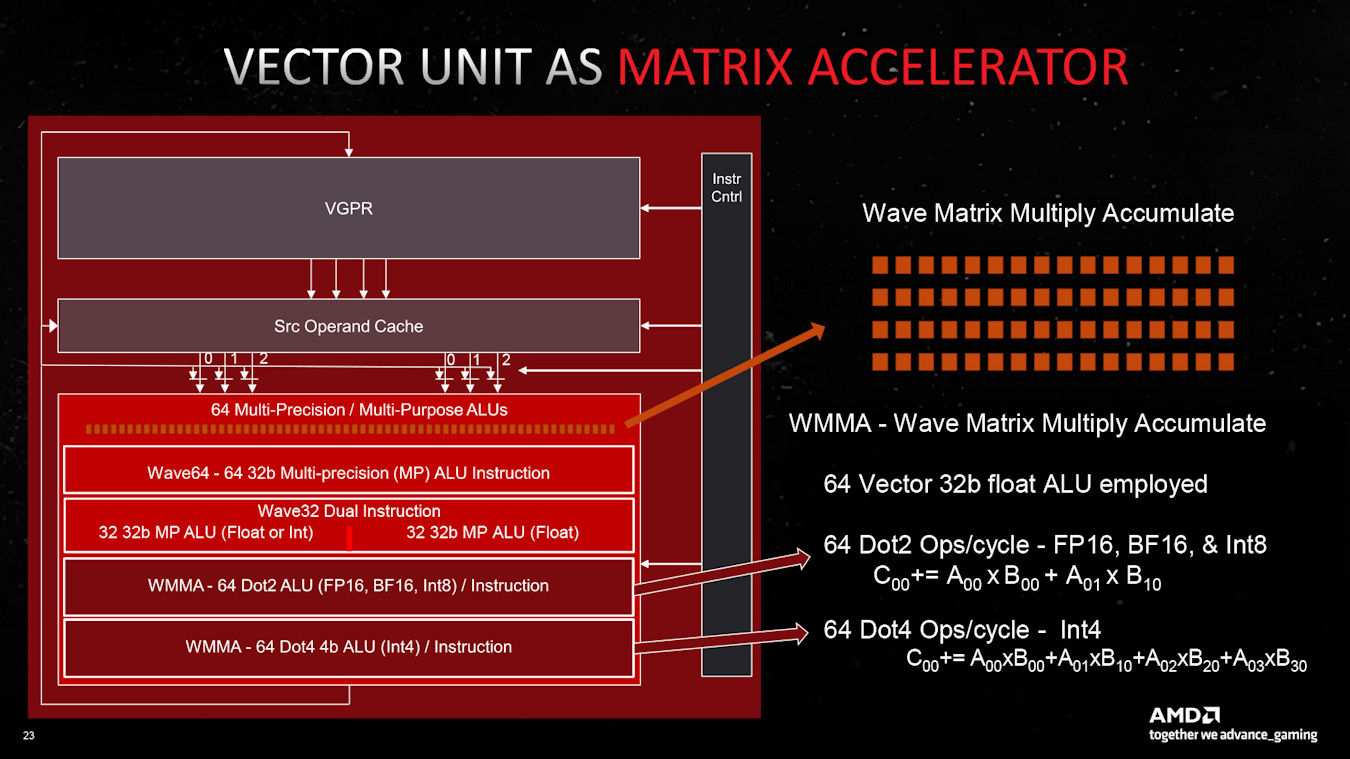
In addition, the CU of RDNA 3 has a new AI accelerated computing unit, and the Vector Unit can be used as a Matrix matrix operation, which can process 64 Dot 2 instructions and 64 Dot 4 instructions per cycle, and has added BFloat16 instruction support, which is comparable to the previous generation RDNA2 Compared with matrix multiplication, the performance is improved by 2.7X, and WMMA matrix multiplication is updated, and 2048 Dot2 instruction operations can be achieved by issuing a single instruction for 32 consecutive cycles.

The RDNA 3 GPU also improves Geometry Shader and Pixel Shader operations. For the first time, the Multi-Draw-Indirect (MDIA) accelerator is added. When executing MultiDrawIndirect and MultiDrawIndexIndirect instructions, the performance is improved by 130% compared with the previous generation, and the CPU requirements are greatly reduced. load.
12 new dedicated Primitive Culling hardware computing units have been added, allowing the GPU to process up to 24 Vertices in the grid per cycle, which is 50% faster than the previous generation. The Geometry Shader’s processing ability has also been greatly improved, and each cycle can handle 6 Primtive corpses and 192 Pixel rasterizers, which is also 50% higher than the previous generation.